
LLMとリアルタイムデータの統合

大規模言語モデル(LLM)とIoTまたはリアルタイムストリーミングアプリケーションを統合することで、ナレッジワーカーの生産性を高め、関連情報や要約情報にアクセスできるようにすることで、ナレッジワーカーに大きな利益をもたらすことができます。 以下のペーパーでは、これを達成する方法、具体的には、VantiqがLLM知識とユーザーインタラクションを既存のエンタープライズワークフローの強化として組み込むのにどのように役立つかを概説しています。
LLMの限界
ナレッジワーカーは、膨大な量の情報を処理してフィルタリングして仕事を遂行する必要があります。 たとえば、フィールドサービス技術者は、100以上の相互に関連する機器を理解して修正する必要がある場合があり、医師は、数十の症状、薬物副作用、診断情報を組み合わせて、潜在的な患者の診断とケア計画に到達する必要があります。 この情報の多くは、マニュアル、教科書、ナレッジベース、その他のソースの形で存在します。 この情報と現在のデータとを組み合わせることは、機械の故障を診断し、問題を解決するための手順を決定したり、患者診断の到達を支援したりするために不可欠です。
ChatGPTや大規模言語モデル(LLM)などのツールは、ナレッジワーカーによって使用されることが増えています。 ただし、ChatGPTとLLMにはいくつかの制限があります。 たとえば、LLMは新しいコンテンツを理解して制作することに優れていますが、トレーニングを受けたデータのコーパスに基づいてのみコンテンツを作成できます。 彼らは膨大な量の情報に対して訓練を受けていますが、この情報は2021年ごろにウィキペディア、GitHubなどの一般的にアクセス可能な情報で訓練されており、ドメイン固有のインテリジェンスがほとんどまたはまったくありません。 さらに、ChatGPTなどのツールは、機器や環境データに関するリアルタイムまたは現在の情報にアクセスできません。 また、歴史的な情報にアクセスできないため、これは閉鎖された検索不可能なソースに常駐することが多く、継続的に更新されます。
LLMのもう一つの制限は、コンテキストサイズです。 コンテキストまたはプロンプトサイズはモデルによって異なります。一般的に2Kトークン(2〜3ページのテキストに相当)から32Kトークン(40〜50ページのテキスト)までさまざまです。 このコンテキストサイズには、クエリ、コンテキスト情報、LLMによって生成された応答の両方が含まれます。 コンテキストサイズ(32K)を大きくしても、コンテキスト内で完全なナレッジベースを提供することは不可能です。
プライバシーは別の懸念事項です。 ChatGPTなどのツールに送信される情報の中には、非常に機密性の高いものもあります。 したがって、患者情報や顧客の財務情報をChatGPTなどのツールに入力することは実行できません。 代替手段として、プライベートLLMなどのソリューションは有用であることが証明されるかもしれません。 現在、GPTやBERTなどのLLMを中心に多くの焦点と議論がありますが、時間が経つにつれて、業界やドメイン固有情報で訓練された非常に特殊なLLMが表示されるようになり、プロンプトに含まれる機密データの主権を確保できるようになるでしょう。
トレーニングカスタムLLMは、必ずしも実用的または必要になるとは限りません。 LLMのトレーニングは、コスト、時間、スキルの観点から見た巨大な事業であり、典型的なエンタープライズ組織はこの機能を持っていない可能性があります。 場合によっては、医療や法律市場など、言語と文脈が非常に特殊であるカスタムLLMを訓練することが有利になる場合がありますが、LLMを効果的に最新の状態に保つことができないままです。 毎分2本の論文が医療分野に公開されると推定されています(https://www.nature.com/articles/nj7612-457a)、毎時間80以上の新しい法律ケースがあります(https://www.uscourts.gov/statistics-reports/federal-judicial-caseload-statistics-2021)。 したがって、カスタムLLMを使用する場合でも、これを最新のナレッジベースと組み合わせることは依然として重要です。 多くの場合、既存のLLMがセマンティック検索と呼ばれるプロセスを使用して求められたときに適切なコンテキスト知識を送信された場合、カスタムLLMは必要ありません。以下に詳しく説明します。
これらのスタイルのアプリケーションや状況をサポートするために、さまざまな技術や手法がこれらの問題に対処できます。 既存の参照資料と知識ベース、機器または患者に関するリアルタイムステータス情報、機器または患者に関する履歴情報、ユーザーからのテキストプロンプトを組み合わせて、LLMをガイドし、目の前の状況に特有のコンテンツを生成する必要があります。
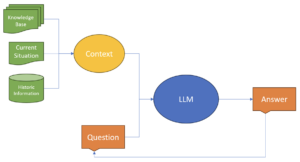
ナレッジベースをセマンティック検索に組み込む
ナレッジベース、リファレンステキスト、その他の形式の文書は企業内にしばしば存在し、ナレッジワーカーはこれらを検索できる必要があります。 従来の検索アプローチはキーワードベースです。 LLMでは、より生産的なアプローチは、セマンティック検索機能を使用して質問に関連する情報を収集し、この追加のコンテキスト情報をコンテキスト/プロンプトの一部としてLLMに表示することです。 セマンティック検索は、質問の意図と文脈の意味を決定するメカニズムを使用し、これを検索クエリとして使用し、データソースで一致する概念を見つけます。
データベースの投入
セマンティック検索問題の前半は、LLMを使用してナレッジベースとドキュメントを埋め込みとしてエンコードすることを含みます。 これらの埋め込みを作成することは非常に計算集約型であるため、通常は効率的な検索のためにベクトルデータベースに保存されます。 ベクトルデータベースは、埋め込みのソースドキュメントなどの埋め込みと関連するメタデータを保存します。 大きな文書は小さな断片またはチャンクに分割され、LLMがより関連性の高い情報で表示されます。
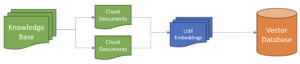
データベースからの取得
質問/プロンプトに関連する関連する文書/知識をユーザーから取得するために、質問は埋め込みとしてエンコードされ、ベクターデータベースに対して類似性検索が実行されます。 このプロセスは、質問されている質問に関連性があるかもしれない文書/チャンクを取得します。

質問、意味検索結果、状況認識を組み合わせる
この時点で、セマンティック検索の結果をユーザーの質問とともにプロンプトに追加するだけでよいのです。 ただし、コンテキスト情報を追加したい場合があります。 たとえば、誤動作している機械からの最後の10分のセンサーデータ、セマンティック検索結果とユーザーの質問を追加して、LLMからの応答を生成することができます。 現在の患者のバイタルサインとセマンティック検索の結果と質問を組み合わせることができます。 また、患者の医療記録や患者が服用している現在の薬物のリストなどの歴史的な情報を、LLMに送信されたプロンプトに追加することもできます。 この情報は、事前にこの情報を知っていることが多いため、おそらくベクトルデータベースには属しておらず、質問に関連付けられているのではなく、質問が尋ねられているコンテキストに関連付けられています。 したがって、この情報をベクターデータベースに追加することは不要で非効率的です。 関係データベースから患者の病歴や薬物データを調べたり、患者名や故障した機器のIDを知ることで、機器のサービス履歴を調べたりするのが効率的です。
ユースケース分類
上記のモデルを使用できるさまざまなユースケース分類があります。 LLMに質問することは非常に計算集約的で比較的遅いです。 LLMは機械の速度ではなく人間の速度で応答する傾向があり、質問への応答には質問と提供されるコンテキスト情報の量に応じて1〜30秒かかります。 LLMは、リアルタイムデータストリームにおける状況の検出に使用すべきではなく、ナレッジワーカー情報を提供し、ナレッジワーカーが必要に応じて情報を絞り込み、要約できるようにするために使用すべきではありません。
スマート通知とアラート
通常、アプリケーションは、関心のある状況が検出されたときにナレッジワーカーに基本的な通知を送信します。この通知には、状況に関する詳細とさらなる情報への可能なリンクが含まれている場合があります。 スマート通知は、LLMとリアルタイム状況情報、1つ以上のナレッジベース、歴史的な可能性を持つ情報と組み合わせて使用し、ナレッジワーカーに初期診断を提供します。 ナレッジワーカーは、提供された情報をさらに絞り込むまたは問い合わせることができます。
コンテキストウェア支援
ナレッジワーカーは、患者や機器を定期的にレビューすることがよくあります。 コンテキストウェアアシスタントは、患者または機器の現在の状態と歴史的な情報や潜在的に知識ベースを組み合わせて、ナレッジワーカーに患者または機器の現在の状態をより洗練されたビューを提供することができます。
VantiqとLLM
Vantiqのリアルタイムアプリケーションは、膨大な量のストリーミングデータを処理して、関心のある状況を検出します。 これらのアプリケーションは、複数のAIやMLプラットフォーム、既存のバックエンドアプリケーションをオーケストレーションして、関心のある状況を検出し、解決に導くことができます。 Vantiqは、関心のある状況の解決におけるLLMを含め、リアルタイムアプリケーションの機能をさらに強化するためにいくつかのLLMベースの機能を追加しました。
セマンティック検索機能
ベクターデータベースを入力して問い合わせを行い、セマンティック検索機能をサポートする機能を提供します。
- 埋め込みのベクターデータベースへの投入と自動作成と保存
- テキスト、PDF、ワードなどの一般的なファイル形式のサポート
- ベクトルデータベースに対してクエリを実行し、結果を追加/結合する機能。
LLM機能へのアクセス
さまざまなLLM機能との統合は、プラットフォームに含まれています。 これらには以下が含まれます。
- いくつかの商用およびオープンソースの大規模言語モデルとの統合
- 開発者が提供しなければならないのはアクセストークンだけであり、モデルをVantiqアプリケーションに統合することができます
- プロンプトテンプレート
- プロンプトの構築は、強力なテンプレートエンジンを使用して定義し、開発者生産性を高めることができます。
- リアルタイム情報、履歴情報、セマンティック検索結果を質問と簡単に組み合わせることができます
これらの機能は、いくつかのLLMとセマティック検索関連のアクティビティパターンを含めることで、Vantiqアジャイルビジュアルイベントハンドラー機能に統合されます。
これらの機能は、Vantiqの既存の機能と組み合わせて、新しいアプリケーションを構築し、これらの機能を既存のアプリケーションに統合することができます。
- メモリ内状態管理 – これにより、データベースではなくメモリ内の会話履歴を管理および維持できます。 これにより、アプリケーションのパフォーマンスが大幅に向上します。 インメモリ状態は、クラスタ全体で自動的に複製することもでき、パフォーマンスコストをかけずにデータベースの信頼性を提供します。
- コラボレーション機能 – Vantiqのさまざまなコラボレーション機能は、LLM機能と統合できます。
- コラボレーションインスタンスを関心のある状況ごとに1つに制限する機能。
- モバイルアプリケーションとの統合
- チャットボット機能との統合
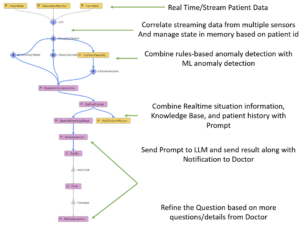
以下は、患者が即時の注意が必要であることを示す状況を探しているさまざまな患者のバイタルサインを管理するシンプルなビジュアルイベントハンドラーの概要です。 状況が検出されると、患者の状態、患者の履歴、医師の診断に役立つナレッジベースからの情報を組み合わせて、最初のプロンプトを定義します。 最初の質問はシステムによってLLMに提示され、すぐに医師に送信されます。 その後、医師はシステムフォローアップの質問を行うことができます。
まとめ
リアルタイムアプリケーション内での大規模言語モデル(LLM)の統合は、知識ワーカーの生産性を大幅に高める可能性があります。 GPTなどのLLMは、新しいコンテンツを理解して制作することで、ナレッジワーカーにとってますます価値あるツールとなっています。 ただし、LLMには制限があり、事前訓練されたデータへの依存やコンテキストサイズに制限があります。
これらの制限を克服するために、セマンティック検索機能を通じてナレッジベースを組み込むことで、LLMに追加に関連する情報を提供することができます。 ナレッジベースと文書をベクターデータベースに埋め込むものとして符号化することで、ナレッジワーカーはクエリに関連する情報を効率的に検索できます。 セマンティック検索結果とリアルタイムステータス情報、履歴データ、ユーザープロンプトを組み合わせることで、LLMからコンテキストリッチな応答を生成できます。
Vantiqは、リアルタイムアプリケーションプラットフォームで、LLM統合とセマンティック検索をサポートする機能を提供します。 このプラットフォームは、ベクターデータベースへの埋め込みの作成と保存を可能にし、効率的なクエリとセマンティック検索を可能にします。 また、さまざまなLLM機能、商用およびオープンソースLLMとの統合、テンプレートエンジンを使用してプロンプトを構築する柔軟性を提供します。
VantiqのLLMとセマンティック検索機能をメモリ内状態管理やコラボレーションツールなどの既存の機能と統合することで、開発者は強力なリアルタイムアプリケーションを構築することができます。 これらのアプリケーションは、ナレッジワーカーに患者や機器の状態をより正確に把握し、スマート通知とアラートを提供し、意思決定プロセスを支援することができます。
全体として、Vantiqなどのプラットフォームが促進するLLMとリアルタイムアプリケーションの組み合わせは、ナレッジワーカーの効率性を高め、関連性の高い要約情報にタイムリーにアクセスできるようにするという大きな期待を持っています。